The speech AI infrastructure to unmute the world
Accesible infrastructure
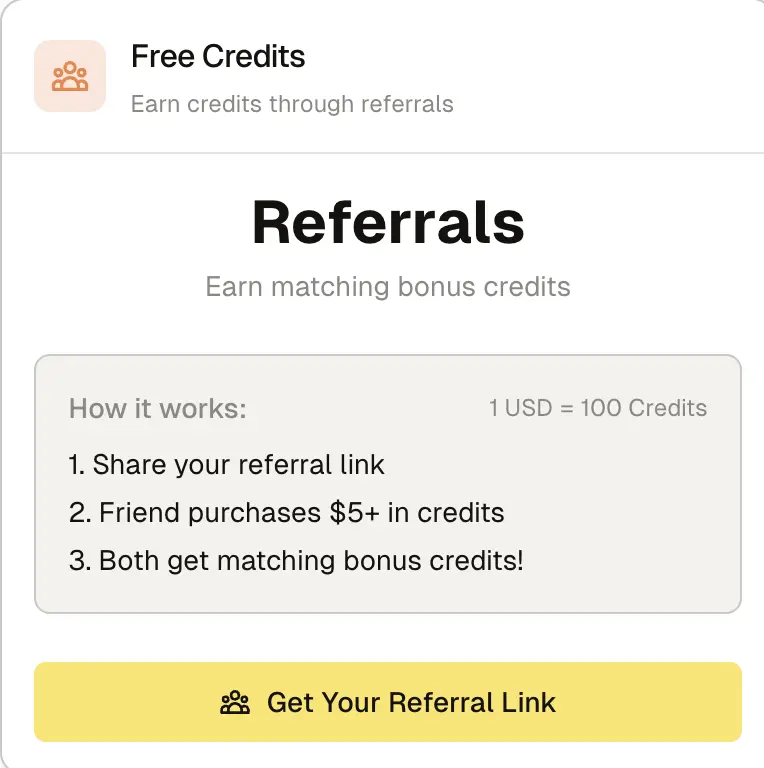
All you need to build with speech AI, everywhere.
Voices without borders
Compliant and cost effective
Simple, scalable adoption
One global API
The radically global speech AI gateway for simple, universal, real-time voice.



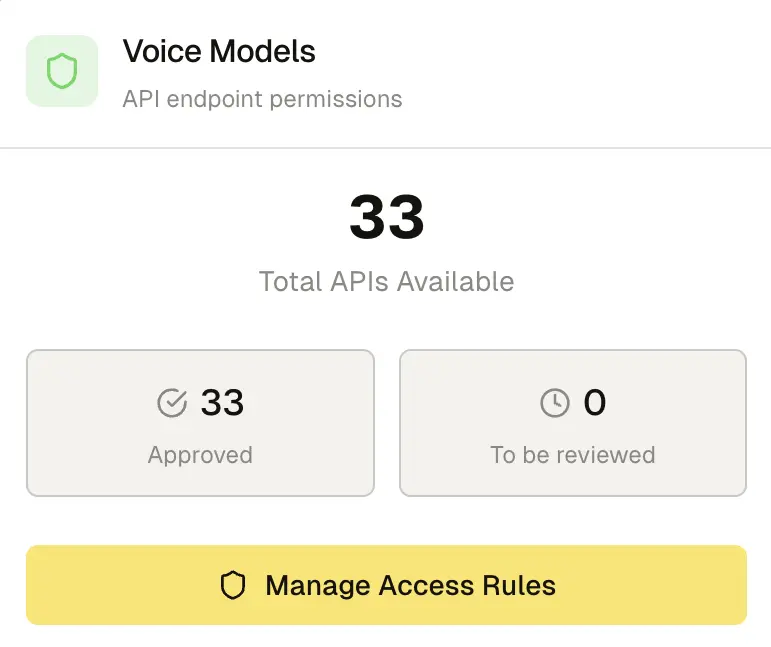
Find the right model, fast.
Filter by language, dialect, professional slang, latency, cost, and data residency. Benchmark in your target region and compare instantly—no vendor maze, no lock-in.
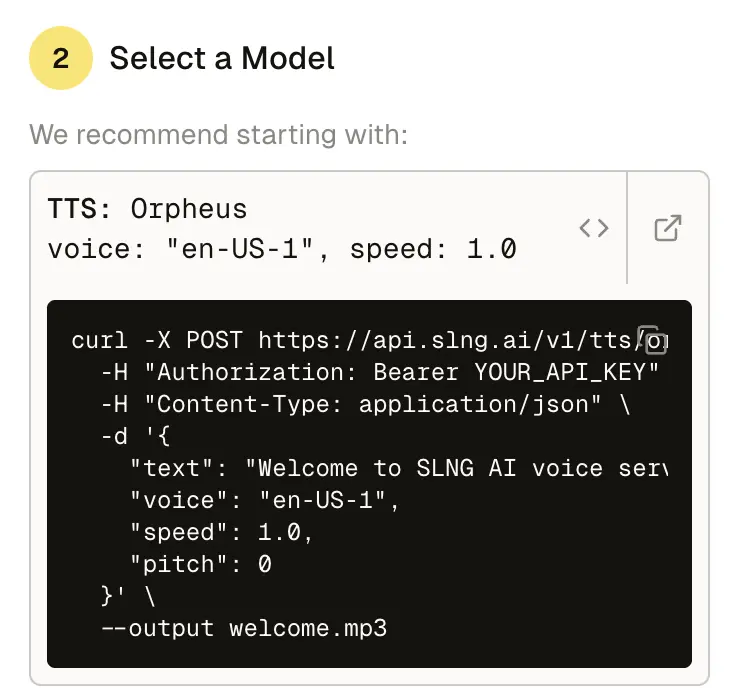
Go live in minutes.
Smart routing places workloads on the nearest compute for low latency. Quickstarts and webhooks make it production-ready from day one, streaming or batch.
Stay in control, globally.
Audit trails and performance dashboards keep everything accountable. A/B test models, switch with one line, and keep costs and SLOs predictable as you scale.
Multi-region
Speech AI where you are.
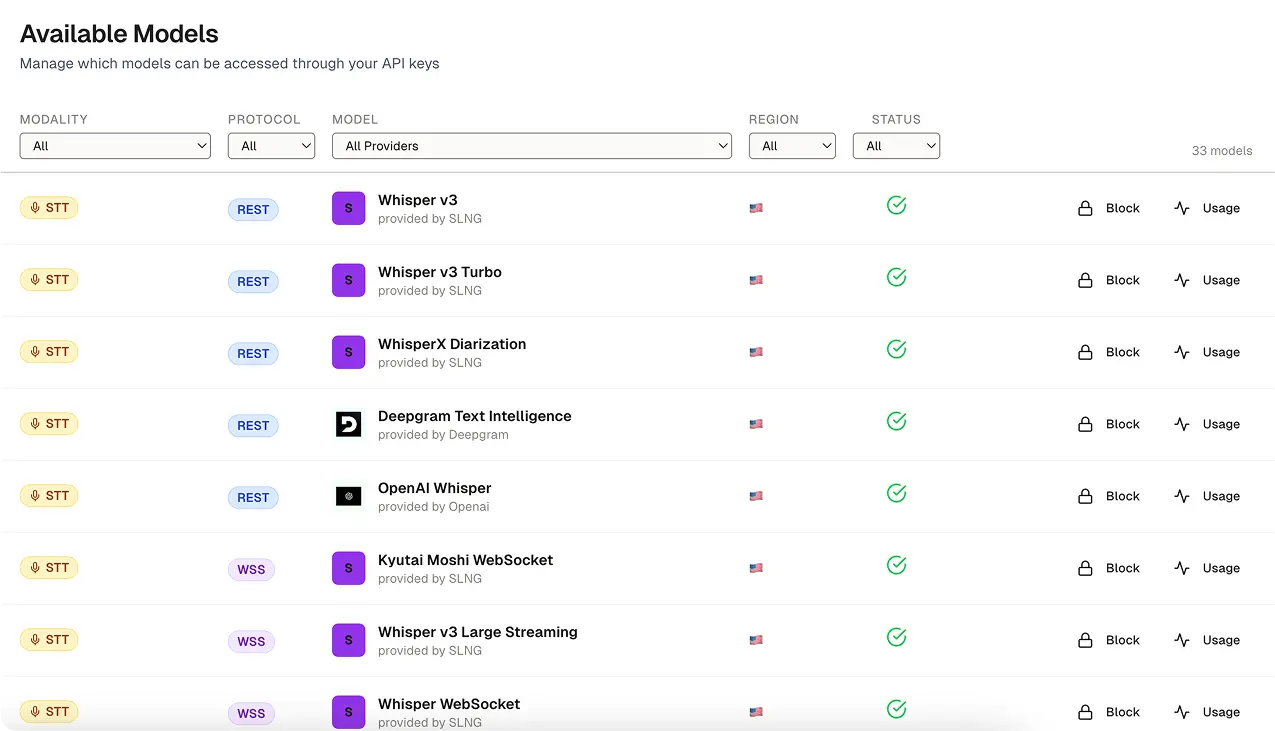
Featured models
All models. One gateway.

Region: US only
Direct Integration
Bring your own key

Region: US only
Direct Integration
Bring your own key

Region: US only
Direct Integration
Bring your own key

Region: US only
Direct Integration
Bring your own key

Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key

Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key

Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key
Region: US only
Direct Integration
Bring your own key
Pricing
Radically accessible.
Cost-effective by design
Predictable and controlled
Accessible to all
Developer Experience
From idea to first audio in seconds, anywhere.

No infra overhead

One-stop API

SDKs and starter kits

JSON in/out & webhooks

Smart Routing
Preferences and dashboard
Compliance by design
Deploy where you need. Stay compliant.

Compliance Hub
AI Co-pilot
Data residency
Certifications
All voices
Global, compliant, real-time.